

ETXL Manifesto. L’ETL professionale fatto con Python
Scrivere programmi o programmare è un’attività molto creativa e soprattutto gratificante se risolve problemi automatizzando attività ripetitive e noiose se svolte manualmente. L’ETL è una di queste. Nella maggior parte dei casi le procedure di estrazione, trasformazione e caricamento (load) sono processi ripetitivi che devono andare avanti nel tempo e funzionare in una macchina (fisica o in cloud) senza intoppi.
Di seguito propongo una lista non esaustiva delle fattispecie risolte costruendo un sistema robusto e completamente automatizzato.
- Avevo bisogno di costruire un DataWareHouse che venisse alimentato estraendo dati da più fonti (varie tecnologie SQL, file Excel e “.csv”), a frequenze diverse. Le sorgenti SQL contenevano alcune tabelle di grosse dimensioni (qualche GB di dati) che richiedevano procedure di change data capture (ovvero caricare nel DWH solo le nuove righe ed aggiornare/cancellare le righe modificare/cancellate nelle sorgenti).
- Avevo necessità di un sistema che ad ogni aggiunta di un file “.csv” (o “.xlsx” o di qualsiasi altro tipo) su una determinata cartella facesse partire una procedura ETL per immagazzinare i dati in un database SQL nel Cloud.
- Avevo bisogno di una procedura che estraesse i dati da una sorgente SQL con tabelle di dimensioni ragguardevoli, trattasse i dati secondo alcune logiche di business per poi immagazzinarli in un file “.parquet” da caricare in un servizio di storage Cloud (Amazon, Google, Azure o altri).
- Mi era stato richiesto un sistema che una volta al giorno leggesse da una specifica cartella i nuovi file “.xml” delle fatture elettroniche (o “.xbrl” del bilancio di esercizio), convertendo, nel caso, i “.p7m” in “.xml”), per poi aggiornare un modello dati presente in un database SQL-
- Avevo necessità di una procedura che, ad ogni aggiunta di una riga in una tabella “anagrafica clienti” di un database SQL, facesse partire una chiamata al servizio Google Map (API) per trasformare latitudine e longitudine in un indirizzo testuale (o viceversa) e completare l’anagrafica con questa informazione.
- Avevo voglia di fare un po’ di ricerca prototipando un sistema che riuscisse ad interagire con le API di Power BI del mio tenant personale, eseguendo query DAX, caricando Push Dataset o facendo partire alla bisogna refresh dei dati.
Per costruire questi automatismi si deve necessariamente interagire con le macchine (fisiche o virtuali) imparando a “colloquiare” amichevolmente con la CPU indicandole cosa fare esattamente e come utilizzare in maniera ottimizzata le varie componenti di cui dispone.
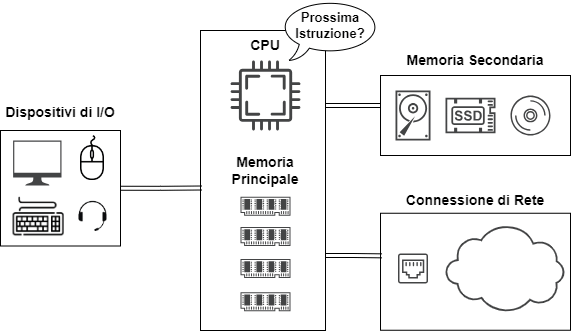
Se si smonta una di queste macchine (un personal computer, un server, un tablet, uno smartphone, arduino, ecc.) ritroviamo nel tavolo generalmente questi tipi di componenti:
- La CPU è progettata per prendere in carico le richieste, adoperarsi per rispondere ed accettare la successiva istruzione. Le CPU hanno raggiunto la capacità di ripetere questo ciclo miliardi di volte al secondo (semplificando è la velocità in Gigahertz della CPU della macchina).
- La memoria principale (principalmente la RAM), veloce quasi quanto la CPU, è utilizzata per immagazzinare le informazioni di cui la CPU ha bisogno per evadere le richieste. La RAM “azzera il magazzino” allo spegnimento del computer.
- La memoria secondaria (dischi rigidi, ssd, memorie usb, memorie ottiche) è utilizzata per conservare le informazioni anche a dispositivo spento. E’ molto più lenta della principale.
- La connessione di rete è utilizzata per scambiare informazioni con altri computer.
- Le periferiche di input\output (schermo, tastiera, mouse, microfono, altoparlanti, touchpad, ecc.) sono dispositivi che servono per interfacciarsi più “umanamente” con il computer.
Per far funzionare tutto questo “ferro” affinché risolva i nostri problemi dobbiamo dire alla CPU cosa deve fare “passo dopo passo”. Non potremo mai comunicarglielo in tempo reale (è troppo più veloce di noi), gli lasceremo una lista delle “cose da fare” scrivendo in anticipo delle istruzioni memorizzate in un file che diventano un programma.
La programmazione è l’arte di scrivere queste istruzioni che, ottimizzando il funzionamento di tutte le componenti del computer, ci permette di velocizzare un’attività o un intero processo.
Il problema è che la CPU non è poi così “amichevole” dato che capisce solo il cosiddetto “linguaggio macchina” ovvero una serie finita di 0 e 1 (000110010.….0000010101010).
Dover programmare in linguaggio macchina sarebbe scoraggiante per chiunque (pochi esclusi) per questo sono nati nel tempo linguaggi che consentono di scrivere programmi con una grammatica ed una sintassi più “umana” che vengono poi “tradotti” in linguaggio macchina.
In base alla modalità di traduzione questi linguaggi di programmazione si dividono in due categorie: interpretati e compilati.
La differenza è semplice, la descrivo con un esempio.
Immagina di essere una CPU e di voler preparare una pizza seguendo una ricetta (il programma) che ti hanno fornito (in un file) in dialetto napoletano (linguaggio di programmazione). Ovviamente non conosci il dialetto napoletano e capisci solo il dialetto aretino (il linguaggio macchina). Puoi sbloccare la situazione in due modi.
Il primo è che qualcuno (il compilatore del linguaggio di programmazione) traduca interamente la ricetta della pizza in aretino e te la fornisca (in un file eseguibile). A questo punto sarai in grado di leggere da solo la ricetta scritta in aretino e preparare la pizza. Farai molto velocemente!
Il secondo modo è che tu abbia un amico napoletano (l’interprete del linguaggio di programmazione) che conosce i dialetti. Quando ti chiedono di preparare la pizza, il tuo amico si siede accanto a te e ti traduce la ricetta in aretino fornendotela passo dopo passo mentre stai preparando il piatto. Arriverai allo stesso risultato ma ti ci vorrà più tempo.
I linguaggi compilati sono quelli più veloci, alcuni esempi: C, C++, Rust e Go.
I linguaggi interpretati sono più lenti dei linguaggi compilati (tuttavia con l’affermarsi della compilazione just-in-time il divario sta diminuendo), alcuni esempi: PHP, Java (semi-interpretato), JavaScript e Python.
Il compilatore just-in-time è l’amico napoletano che ti si siede accanto con già dei fascicoletti tradotti in aretino dei vari passaggi della ricetta. Ti fa comunque perdere del tempo, ma sei in buona compagnia e il lavoro lo porti a termine felicemente.
ETLX tratta di ETL professionale fatto con Python. Perché alla data del presente contributo è preferibile Python?
- Perché ha una sintassi estremamente semplice ed
una curva di apprendimento agevole.
- Perché è open source.
- Perché puoi usare gratuitamente le librerie (pezzi di codice che programmatori professionisti hanno scritto per risolvere uno specifico problema).
- Perché il numero delle librerie è nell’ordine delle centinaia di migliaia e coprono qualsiasi fattispecie.
- Perché ha una comunità molto attiva sul web con
una grande ricchezza di contenuti e quindi…
- sei adeguatamente supportato sia da principiante che da esperto;
- sistemi come ChatGPT, Bard o similari sono estremamente performanti nel supportarti.
- Perché Python è il linguaggio dell’Intelligenza Artificiale e del Machine Learning.